t3n SEO-Check: 4 Wege, Google-Rankings zu verhindern
")
Zusammen mit Christian B. Schmidt testet t3n eure Website auf Optimierungsbedarf. (Bild: Shutterstock)
Im t3n SEO-Check mit Christian B. Schmidt geben wir euch jede Woche Einblicke in die Suchmaschinenoptimierung anhand von Praxisbeispielen. Reicht eure Seite ein und lasst sie kostenlos checken. In der aktuellen Folge erklärt euch Christian, welche Fehler Rankings bei Google verhindern, und was ihr dagegen tun könnt.
Bei 100 SEO-Checks ist immer eine Handvoll dabei, bei denen der Googlebot durch die Einstellungen der Webmaster am Crawling oder der Indexierung gehindert wird. Diese Fälle sind besonders bitter, weil den Website-Inhabern dieser Umstand oft gar nicht bewusst ist. In diesen Fällen ist es also besonders einfach, Abhilfe zu schaffen. Im folgenden umgekehrten Ratgeber zeige ich vier Aspekte, auf die man achten sollte, um Google-Rankings für die eigene Website nicht zu verhindern. Gleichzeitig kann die Liste genutzt werden, um das Vorgehen des Googlebots besser zu verstehen und zu steuern, gerade für den Fall, dass man einen Inhalt nicht in den Suchergebnissen wiederfinden will.
Das Crawling über die robots.txt verbieten
Die robots.txt ist eine der ältesten Methoden zur Steuerung der Suchmaschinen-Crawler. Das „Robots Exclusion Standard Protokoll“ (REP) wurde 1994 veröffentlicht und legt fest, dass Suchmaschinen vor dem Crawlen einer Websites zunächst im Root-Verzeichnis nach einer Datei mit dem Namen „robots.txt“ suchen. Diese kann Regeln enthalten, die das Crawling bestimmter Dateien oder Verzeichnisse für alle oder einzelne Roboter verbieten. Zwar halten sich die großen Suchmaschinen wie Google an die Anweisungen zum Crawling, allerdings muss das nicht unbedingt die Indexierung einer Seite verhindern. Wird eine Seite beispielsweise extern verlinkt, speichert Google sie dennoch in seinem Index, allerdings ohne den eigentlichen Inhalt, wenn das Crawling per robots.txt verhindert wird.

Diese robots.txt hindert alle Suchmaschinen-Robots am Crawling der gesamten Website. (Screenshot: Christian B. Schmidt)
Die Indexierung über die Meta-„robots“-Angabe verhindern
Anders als bei der robots.txt, kann über den Meta-Tag „robots“ auch die Indexierung verhindert werden. Dieser Tag wird im Bereich des HTML-Dokuments unter den Meta-Angaben hinzugefügt. Die Angabe „noindex“ beim Meta-Robots-Tag führt dazu, dass der Googlebot die Seite nach dem Crawlen nicht im Google-Index speichert. Das kommt häufig bei internen Suchergebnissen oder Kategorie-Filterseiten zum Einsatz, da diese für die Suchergebnisse weniger relevant sind. In den meisten Fällen sollte man jedoch keine Unterseiten, geschweige denn die Startseite, auf „noindex“ setzen, denn so verhindert man ganz sicher, dass sie in den Suchergebnissen erscheinen.

Die „noindex“-Angabe im Meta-Robots-Tag verhindert die Aufnahme der Seite in den Google-Index. (Screenshot: Christian B. Schmidt)
Falscher Einsatz vom Canonical-Tag
Der Canonical-Tag wurde geschaffen, um Suchmaschinen die Erkennung von doppelten Inhalten zu erleichtern. Er wird wie Meta-Tags ebenfalls im Head-Bereich einer HTML-Seite integriert. Er stellt quasi einen Link für den Googlebot auf die Originalversion eines Inhalts her, der identisch unter verschiedenen URL abrufbar ist. Der falsche oder widersprüchliche Einsatz kann jedoch weitreichende Folgen haben. Seiten, die per Canonical nicht auf sich selbst referenzieren, werden weiterhin von Google gecrawlt, aber in der Regel nicht indexiert. Da die Canonical-Angabe lediglich eine Empfehlung für die Suchmaschine darstellt, kann sie sich auch anders verhalten, als vom Webmaster vorgeschlagen. Das ist vor allem bei falschen Einsatz der Fall.

Der Canonical-Tag verweist auf eine andere Schreibweise der URL (mit „https“), allerdings empfiehlt sich stattdessen eine permanente 301-Weiterleitung. (Screenshot: Christian B. Schmidt)
Widersprüchliche Weiterleitungen
Weiterleitungen über den HTTP-Header sind ein gängiger Weg, um User von veralteten URL auf ein neues Ziel mit vergleichbarem Inhalt weiterzuleiten. Gerade bei Standardfällen wie der Umstellung von HTTP auf HTTPS oder der Festlegung auf eine Default-Subdomain wie www empfiehlt sich eine permanente Weiterleitung per HTTP-Code 301. Anders als der Canonical-Tag gibt eine „harte“ Weiterleitung Suchmaschinen ein ganz klares Signal, eine URL durch eine andere zu ersetzen. Umso vorsichtiger sollte man mit dieser Anweisung umgehen. Gerade wenn eine Weiterleitung anderen Angaben widerspricht, kann es schnell zu Problemen führen.
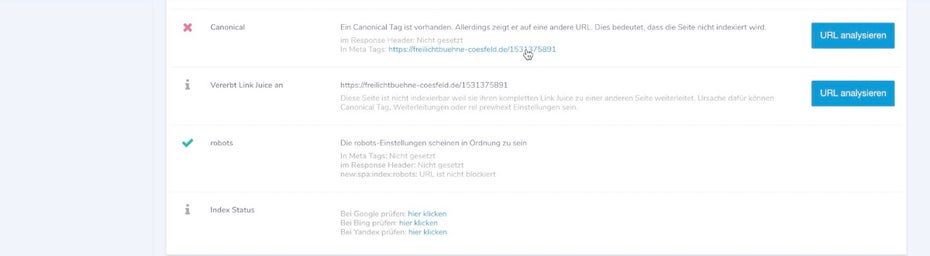
Hier verweist der Canonical-Tag der Startseite auf eine Unterseite… (Screenshot: Christian B. Schmidt)
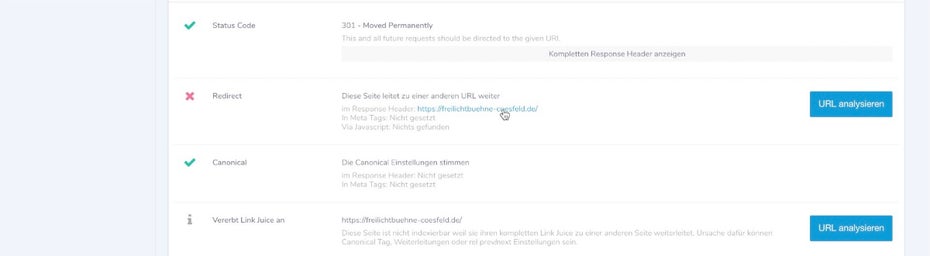
… die wiederum auf die Startseite permanent weiterleitet (Screenshot: Christian B. Schmidt)
Fazit: Vorsicht bei robots.txt, Meta-Robots, Canonical und Redirects
Wie ich anhand der Beispiele beim t3n SEO-Check diese Woche zeige, gibt es viele Fallstricke, die dazu führen können, dass Seiten gar nicht von Suchmaschinen gelistet werden. Ein Blick in den Quelltext oder die Prüfung durch ein einschlägiges SEO-Tool kann sich also lohnen, wenn die erwünschten Google-Rankings ausbleiben. Wer sich für alle Details des dieswöchigen t3n SEO-Checks interessiert, kann sich die aktuelle Folge nachfolgend ansehen:
Ich soll eure Seite durchleuchten und eure Problemzonen aufdecken? Dann reicht jetzt eure Seite für einen kostenlosen SEO-Check ein.
Jetzt Seite einreichen! Christian B. Schmidt optimiert seit 1998 Websites und ist Gründer der SEO-Agentur Digitaleffects aus Berlin. In seiner werktäglichen Podcast- und Videoreihe SEO-Driven führt er in diesem Jahr gratis SEO-Checks für 1.000 Websites durch. Der t3n SEO-Check mit Christian B. Schmidt gibt euch wöchentlich kostenlose Starthilfe.
Christian B. Schmidt optimiert seit 1998 Websites und ist Gründer der SEO-Agentur Digitaleffects aus Berlin. In seiner werktäglichen Podcast- und Videoreihe SEO-Driven führt er in diesem Jahr gratis SEO-Checks für 1.000 Websites durch. Der t3n SEO-Check mit Christian B. Schmidt gibt euch wöchentlich kostenlose Starthilfe.

Ich verstehe nicht, warum ich überhaupt einen Canonical Link brauche, wenn der Inhalt nicht dupliziert veröffentlicht wird? Wo ist der Sinn? Kann mir das jemand erklären?
Ich verstehe, warum ich ihn brauche, wenn ich Inhalte auch an anderer Stelle erreichbar mache, aber warum dann nicht nur für die Seiten? Warum braucht den jede normale Seite?
Hey Peter, ganz einfach: natürlich veröffentlichen die wenigsten ihre Inhalte bewusst unter verschiedenen URLs, doch viele CMS produzieren von ganz allein doppelte Inhalte. Auch der Einsatz von Trackinglinks wie Googles UTM-Parameter zur Nachvollziehbarkeit von Traffic-Quellen in Analytics können dafür sorgen, dass ein identischer Inhalt unter vielen unterschiedlichen Links abrufbar ist. Es macht also aus diesen Gründen fast immer Sinn über den Canonical-Tag die Originalquelle anzugeben. Ich hoffe, meine Antwort hilft Dir weiter. In meinem Youtube-Channel findest Du weitere Videos mit Praxisbeispielen zum Thema: https://www.youtube.com/user/cbschmidtde/search?query=canonical
Das bedeutet aber auch, dass ich ihn eigentlich eben NUR dann brauche, wenn es doppelte Inhalte gibt, oder? Weil das aber immer mal wieder aus Versehen bzw. unbewusst vorkommen kann, baut man ihn am besten einfach immer und überall ein, richtig?
Möchte es ja nur mal verstehen :)
So wird es in der Regel empfohlen, ja. Wichtig ist halt, dass die Logik dahinter auch richtig funktioniert und nicht solche Probleme entstehen, wie ich sie oben bspw. beschrieben habe.
es ist nur eine Empfehlung und kein Muss.
da gehört schon sehr vielm mehr dazu, damit du deswegen aus Serp raus fliegst. ;)
Warum bindet ihr hier ein Facebook Video ein und nicht eins das für jedermann verfügbar ist? YouTube?
VG,
Dirk
Hey Dirk, Du kannst das Video natürlich auch auf Youtube anschauen: https://www.youtube.com/watch?v=kZ4hd7f7YJ0 Viel Spaß!
So wird es in der Regel empfohlen, ja. Wichtig ist halt, dass die Logik dahinter auch richtig funktioniert und nicht solche Probleme entstehen, wie ich sie oben bspw. beschrieben habe.
Hallo,
was mich in Sachen „doppelter Kontent“ mal echt interessieren würde sind Fotos. Viele illustrieren ja Seiten mit Fotos von pixabay oder Fotolia usw. Wie wird ein „hinlänglich bekanntes Foto“ seitens der Suchmaschinen bewertet? Führt das zur Abwertung, weil der Google-Bot denkt „gäääähn, kenn ich schon?“ oder spielt wirklich nur der Text eine Rolle?
Gruß Gabriel
Hey Gabriel, für die Website stellen doppelte Bilder meines Erachtens kein Problem da, hier geht es primär um den Textinhalt. Doch bei der Bildersuche sieht es schon wieder ganz anders aus. Hier erkennt Google nach eigener Aussage Stockfotos sehr wohl, selbst wenn sie unter verschiedenen Namen, in unterschiedlichen Größen oder selbst leicht verändert hochgeladen werden. Dabei muss jedoch nicht immer die Originalquelle als Gewinner in der Bildersuche hervorgehen, einige SEOs manipulieren das auch zu ihrem Vorteil mit fremden Bildern. Ich hoffe, das hilf Dir weiter. Gruß CBS
Hallo Christian, danke für Deine Antwort.
Der Hintergrund meiner Frage war auch – ich arbeite als Fotograf. Hier ist man immer wieder seitens von Werbeagenturen und Kunden mit der Frage konfrontiert: Lohnt sich das Geld für den Fotograf, oder nehmen wir Stock-Fotos. Andres gefragt – ist der Fotograf aus SEO-Aspekten sein Geld wert. Ich verweise immer auf bis zu 25% Traffic durch die Bildersuche. Wäre – aus meiner Sicht – natürlich schön gewesen, wenn ich auch noch darauf hinweisen hätte können, dass Stockbilder auch den Text abwerten ;-)
Gruß Gabriel
Hey Gabriel, ich denke, es gibt vielen Gründe, die für oder gegen Stock-Material sprechen, genauso wie es für und wider hinsichtlich Fotografen gibt. Ich glaube SEO allein ist hier kein gutes Argument, denn zu einem guten Ranking in der Bildersuche gehört ja auch viel mehr, als nur ein einzigartiges Bild. Ich kann Dir zum Thema Bilder SEO mein passendes Video empfehlen: https://www.youtube.com/watch?v=6IFCbqvmpQI — Darin verweise ich auch auf den geschätzten Kollegen Martin Mißfeld, der unter https://www.tagseoblog.de/ viel zum Thema schreibt. Liebe Grüße aus Berlin, Christian
Hallo,
das ist mal wieder eine sehr geile Aktion von Euch!!! t3n ihr seid einfach super!!!
Und Christian und seine Agentur kannte ich auch noch nicht – sehr stark – Danke!!!
Ich habe da auch mal eine konkrete „SEO-Spezial-Frage“:
Zum Hintergrund – unter „Online Marketing Hannover“ und unter „Webdesign Hannover“ rankt unsere Seite sehr gut.
Allerdings unsere Landingpage https://onma.de/werbeagentur-hannover/ verhält sich sehr seltsam – seit gestern ist sie aktuell gar nicht mehr zu finden – zuvor war sie ganz lange unter „Werbeagentur Hannover“ auf Seite drei. Die Snippets werden – wenn die Seite gezeigt wird – auch nicht richtig dargestellt – wir meinen onpage technisch alles richtig und seo-optimal ausgeführt zu haben.
Hey Winni, danke erst mal für Dein positives Feedback, das freut mich natürlich besonders. Ich habe mir Eure Seite eben kurz angesehen und dabei ist mir aufgefallen, dass es in der Vergangenheit wechselnde URLs zu „Werbeagentur Hannover“ gab. Diese findet man auch recht leicht über die site-Suchabfrage: https://www.google.de/search?q=site%3Aonma.de+intitle%3A%22Werbeagentur+Hannover%22
Außerdem ist mir aufgefallen, dass Ihr die Werbeagentur-Seite zumindest von der Startseite auch nirgendwo verlinkt. Wenn dies eine wichtige Seite für Euch ist, solltet Ihr sie in Euere Navigation aufnehmen, um die interne Verlinkung zu verbessern.
Ansonsten kann es natürlich unzählige Gründe haben, warum eine Seite nicht mehr oder nicht mehr so gut rankt. Das müsste man sich noch mal im Detail genauer ansehen. Habt Ihr denn Eure Seite schon eingereicht?
https://digitaleffects.de/t3n/ Gruß CBS
GROSSARTIG – setzen wir um!
Beste Grüße und ein herzliches Dankeschön!